Scalable learning of graphical models
An ECML/PKDD 2015 Tutorial
14:00 - 15:30; 16:00 - 17:45 on Monday, the 7
Infante room
Your tutors

Geoff Webb
Geoff Webb is Director of the Monash University Center for Data Science. He was editor in chief of Data Mining and Knowledge Discovery from 2005 to 2014. He has been Program Committee Chair of both ACM SIGKDD and IEEE ICDM, as well as General Chair of ICDM. He is a Technical Advisor to BigML Inc, who are incorporating his best of class association discovery software, Magnum Opus, into their cloud based Machine Learning service. He developed many of the key mechanisms of support-confidence association discovery in the 1980s. His OPUS search algorithm remains the state-of-the-art in rule search. He pioneered multiple research areas as diverse as black-box user modelling, interactive data analytics and statistically-sound pattern discovery. He has developed many useful machine learning algorithms that are widely deployed. He received the 2013 IEEE Outstanding Service Award, a 2014 Australian Research Council Discovery Outstanding Researcher Award and is an IEEE Fellow.

François Petitjean
François Petitjean is a Researcher at the Center for Data Science at Monash University. His research area include data mining and machine learning, and focuses on the analysis of large and high-dimensional data. He obtained his PhD in 2012 working for the French Space Agency and then joined Geoff Webb's machine learning team at Monash University. His main results include:
- Chordalysis: a method to learn the structure of graphical models from data with 1,000+ variables
- DBA: a method to average time series under time warping
The pitch
From understanding the structure of data, to classification and topic modeling, graphical models are core tools in machine learning and data mining. They combine probability and graph theories to form a compact representation of probability distributions. In the last decade, as data stores became larger and higher-dimensional, traditional algorithms for learning graphical models from data, with their lack of scalability, became less and less usable, thus directly decreasing the potential benefits of this core technology. To scale graphical modeling techniques to the size and dimensionality of most modern data stores, data science researchers and practitioners now have to meld the most recent advances in numerous specialized fields including graph theory, statistics, pattern mining and graphical modeling.
This tutorial will cover the core building blocks that are necessary to build and use scalable graphical modeling technologies on large and high-dimensional data.

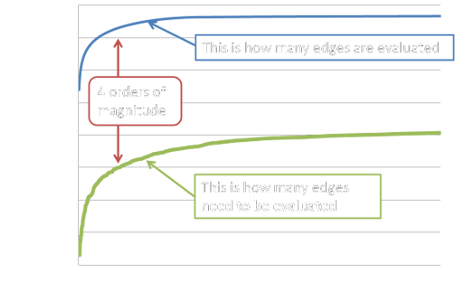
Schedule
| Time | Duration | Content | Specific skills |
|---|---|---|---|
| 14:00 | 20min | Introduction | Definition and usefulness of graphical models |
| 14:20 | 25min | Graphical Models 101 | Main families of graphical models. Issues for scaling |
| 14:45 | 20min | Graph theory | What are decomposable models? Why are they useful? Standard associated algorithms. |
| 15:05 | 20min | Scoring decomposable models | How to score decomposable models? |
| 15:30 | 30min | Break | How good the coffee is in Porto How to score decomposable models? |
| 16:30 | 25min | Efficient search | What are clique-graphs? How to perform greedy search over graphical models with 1,000+ variables? |
| 16:55 | 20min | The nitty-gritty | How do we make it really work? How to count efficiently? How not to do the same thing twice? |
| 17:15 | 15min | Use cases | What can we do once we have graphical models for high-dimensional data? |
| 17:30 | 15min | Wrapping up! | Summary and description of the main remaining issues in the field |